You search your own topic on Google. Your site is on page one. You ask ChatGPT the same question and a different site gets cited. Sometimes a much weaker one. You check Perplexity. Same result. You try Gemini. Still nothing.
This is not an anomaly. It is the defining frustration of 2026 for anyone who built their visibility strategy around Google rankings.
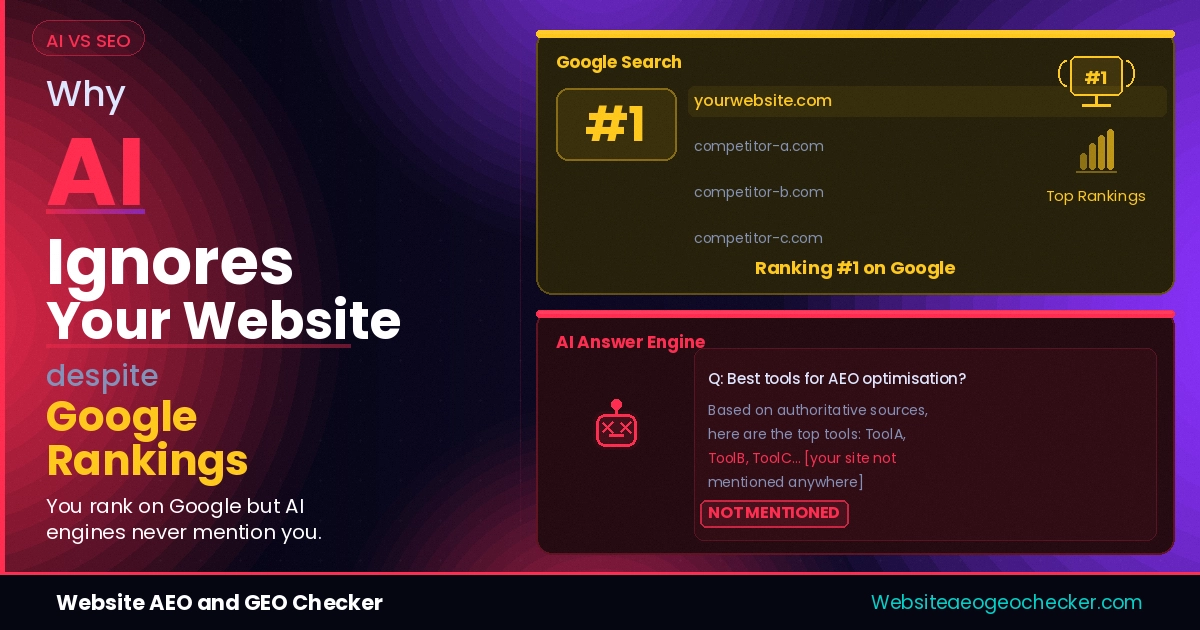
According to 5W Research, the overlap between top Google ranking pages and AI-cited sources has collapsed from 70% to under 20% as of late 2025. The two systems are diverging fast, and they reward almost entirely different things. 28% of ChatGPT's most-cited pages have zero organic visibility on Google. A site you have never heard of, with no meaningful Google presence, can be cited repeatedly in AI answers while your page one result gets ignored.
It's a matter of structure. Google organizes an entire page. AI engines quote distinct passages. Authority and relevance are required to rank. Extractibility is required to get cited. Most SEO-optimized sites don't offer structure and machine-readable signals, which are required for extractability.
Each of the seven reasons below has a diagnosis and a fix you can act on today.
Google Rankings and AI Citations Are Built on Different Foundations

Google has spent 25 years refining a ranking system based on backlinks, keyword relevance, domain authority, and technical performance. It rewards topical depth, external references, and mobile performance.
AI engines work differently. They do not rank results in order. They cite sources inside a synthesized answer. The criteria for selecting a source are: is the page accessible, does it provide a clear answer, is the author reliable, and is the content organized for retrieval? Backlinks are not considered, and neither is domain authority. The citation layer is indifferent to the many SEO signals.
AI platforms cite content that is 25.7% fresher than what appears in organic results, with ChatGPT showing the strongest recency bias. Structure matters more than length. Extractability matters more than authority. The criteria are different, and the fixes are different. For a side-by-side breakdown of how these systems diverge, read our guide on the differences between AEO, SEO, and GEO.
Reason 1 to Reason 3: How AI Engines Read Your Pages
These three reasons are about what AI engines find when they land on your content. The page loads. The bot has access. But the content itself is not giving the engine what it needs to cite you.
Reason 1: Your pages do not open with a direct answer
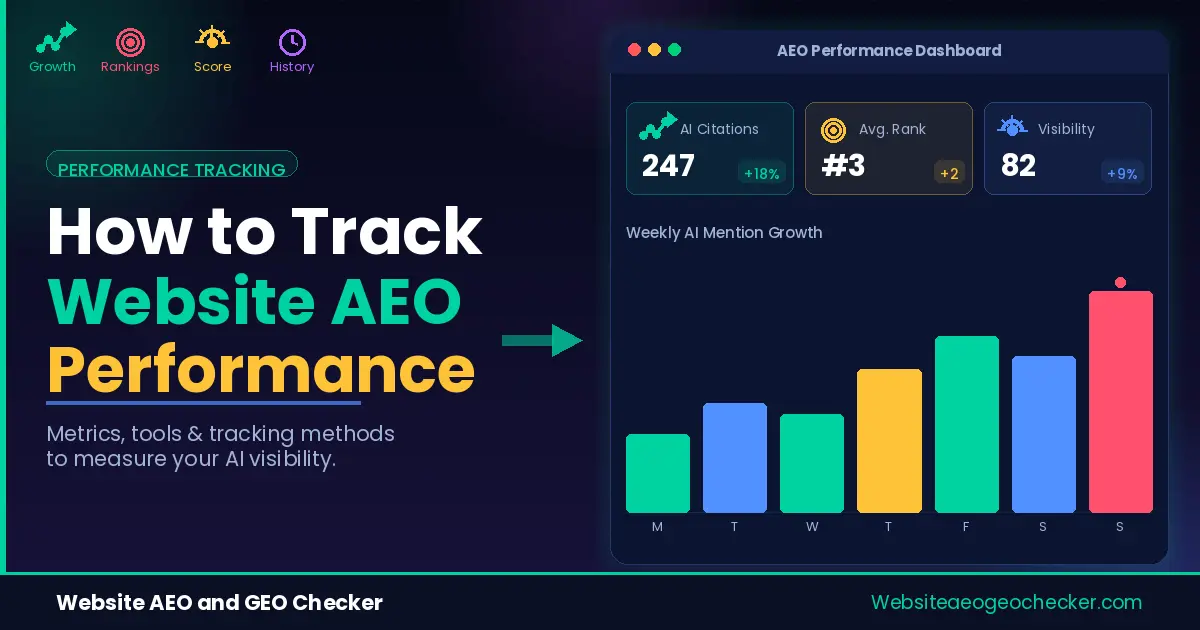
44.2% of citations attributed to a large language model (LLM) are from the first 30% of the page. AI LLMs cite mostly the first section of a page. If the first section of your page is a lengthy introduction or a history of the topic, then page real estate is granted to the competitor, who is providing the answer.
AI engines scan for an extractable passage close to the top. If they find one, they cite the page. If the first 100 words are context and preamble, they move on. The fix is not a rewrite. It is a reorder. Move your direct answer to the first two sentences. Move the context to the second paragraph. Read the exact method in our answer-first content guide for AI engines.
Real example: Yemi, a freelance copywriter who built a content site covering productivity tools, had page-one Google rankings on six keywords. She had zero citations across ChatGPT, Perplexity, and Gemini. She ran the Free Website GEO Checker on her top five pages and found every page opened with a motivational paragraph about why the topic mattered before answering the actual question. She rewrote just the opening paragraph of each page to lead with a direct answer and reformatted two pages to use question-led H2 headings. Within 5 weeks, her page on time-blocking methods started appearing in Perplexity answers for that query.
Reason 2: You have no structured data
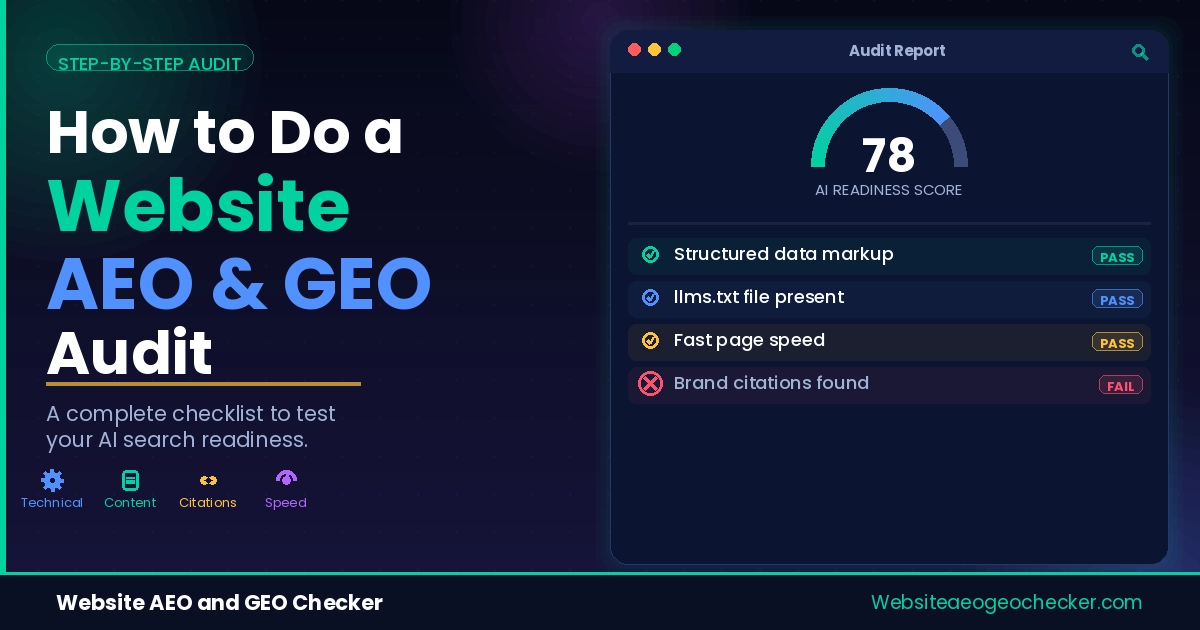
Only 38% of AI citations come from Google's top-10 results. The pages filling the remaining 62% tend to share one thing: structured data that makes content machine-readable in a format AI retrieval pipelines understand directly.
AI engines, using FAQPage schema, recognize which questions are answered and how. The article schema provides the date, the author, and a summary of the content. The organization schema provides the name of the entity that runs the site. Without these, regardless of how high the page rank is on Google, it is just an anonymous block of text.
According to Google's structured data documentation, schema markup helps systems understand your content's context and credibility signals. AI engines use the same markup for the same reason. Start with FAQPage on every page that has a question-and-answer section, then add Article schema to every post.
Reason 3: Your content sections are not self-contained
AI engines extract passages, not pages. When they pull a citation, they take a paragraph or a section and present it as a standalone answer. If your paragraphs require surrounding text to make sense, they cannot be cited independently.
Each section should stand alone. Every paragraph should have its point at the start. The rest of the paragraph should support the point. Someone should be able to read just the paragraph and fully understand the point. This style of writing is called the inverted pyramid. This style improves citation frequency the most out of all the styles below.
The sites we audit that are cited most frequently in AI answers are not the most authoritative or the most comprehensive. They are the most extractable. Every paragraph reads like a standalone answer. That is the pattern. - Website AEO and GEO Checker
Reason 4 to Reason 5: How AI Engines Find Your Pages
These two reasons happen before the engine reads your content at all. The crawl either fails or finds no guidance, and the page never enters the citation pool.
Reason 4: AI crawlers are blocked in your robots.txt
This is the most common reason why we see total AI invisibility when we check a site. It may be the result of an update from a security plugin, a change in a CDN, or a wildcard disallow rule. This all may be done without the site owners knowing and would block the GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, etc., from accessing their site.
The distinction between training crawlers and retrieval crawlers matters here. GPTBot and ClaudeBot train foundation models. OAI-SearchBot and Claude-SearchBot power live retrieval citations in real-time answers. You can block training crawlers while allowing retrieval crawlers, giving you citation visibility without contributing to model training. Most sites have not made this distinction at all. Use the Free robots.txt Checker to see exactly which bots are blocked on your site right now.
Reason 5: You have no llms.txt file
llms.txt is a plain text file at yourdomain.com/llms.txt that tells AI systems which pages on your site are most important and how you want your content used. It is the AI-era equivalent of a sitemap. Adoption is still low enough that having one gives you a clear signal advantage over most competitors in your niche.
It takes under 20 minutes to create. Validate yours with the Free llms.txt Checker and read the detailed guide on what llms.txt is and why your site needs one in 2026.